

What is a robot.txt? It is a question that everybody is asking. This tool is handy these days. So, more and more people are asking about it.
This article will lay down an essential guide to robots.txt for you so that it can be easily understandable for you to use.

Not only this, but we will highlight some other aspects like its structure, how it guides crawlers, some tips for SEO robot.txt, and much more. You should also check out Google Gives Sites More Indexing Control With New Robots Tag.
Contents
Unveiling Robots.txt

In the root directory of a website, there is a plain text file called a robots.txt file. It contains instructions for search engine bots. The robots.txt file is the outcome of a decision. Early search engine creators make it.
It is not an official standard established by any standards organization. Major search engines follow it.
Which pages or portions should be crawled and indexed and which should be disregarded are specified in the robots.txt file.
It allows them to govern access, restrict indexing to specific regions, and control the crawling rate. This file aids website owners in controlling the behavior of search engine crawlers.
It is a public document with voluntary compliance requirements. It is a potent tool for directing search engine bots and affecting the indexing procedure.
What does robot.txt do? Search engines cache the contents of the robots.txt. They don’t have to download it continually. They typically update it several times each day. As a result, modifications to instructions are reflected fast.
By crawling pages, search engines find and index the web. They locate and follow links as they crawl. Using this method, they travel from sites A to B to C.
However, a search engine will open the robots.txt file for a domain before visiting any pages there. They can then see which URLs on that website they are permitted to access and which they are not.
Decoding The Structure of Robots.txt

Here, firstly, we are going to discuss how to create a robot.txt. This is the first thing one should know while working on anything.
The plain text editor of your choice can generate a new robots.txt file. Recall to employ a simple text editor solely.
Ensure you’ve erased the text but not the file from any existing robots.txt files.
It would be best if you first got accustomed to some of the grammar in a robots.txt file.
We will walk through creating a basic robot.txt file.
- Set the user-agent term first. We’ll configure it to apply to all web robots.
- Put an asterisk (*) after the user-agent word to accomplish this.
- Type “Disallow:” after that, but don’t type anything else.
- Web robots will be instructed to crawl your entire site because there is nothing after the prohibition.
Even though it seems so easy, these two lines are doing a lot. You can, but are not required to, link to your XML sitemap.
This is what a robot.txt file looks like –
Sitemap: https://yoursite.com/sitemap.xml
See also: What is a robots.txt file?
Regulating Access

You must first type your instructions into a text file. The text file must then be added using Cpanel to the top-level directory of your website.
Always place your live file after the “.com/” in your URL. The crawlers wouldn’t even bother looking for it if it were located like this. And none of its instructions would be carried out.
Make sure each subdomain has its robots.txt file if you have any. When conducting SEO audits, it is crucial to review the directives for the training subdomain as they have their own unique set of instructions.
Setting Boundaries

A robots.txt file should be present because some analytics tools may mistakenly report inaccurate performance since they will perceive a 404 response to a request for a missing robots.txt file as an error. What exactly does that robots.txt file contain? The main issue is that.
When should you use a robots.txt file? We are going to answer this question as well.
- Preventing crawlers from accessing private areas of your website.
- Saves scripts, utilities, and other sorts of code from being attempted to be indexed by search engines.
- Stops duplicate material from being indexed on a website, such as “print” versions of HTML pages
- Automatic XML Sitemap discovery.
How to check robots.txt? Crawlers will always search the root of your website for the robots.txt file; for instance, adding “/robots.txt” to your domain’s address will do. You still need to get a robots.txt file if nothing appears.
robots.txt disallow directory is something to look at as well. You will list the URLs that should be prohibited in this file section. Typically, the syntax for this is as follows:
Disallow: [URL or directory]
Therefore, you must include “/privacy-policy/” to your forbidden entry to prohibit access to that directory.
In your robots.txt file, you can also use wildcards to ban many URLs at once.
Guiding Crawlers
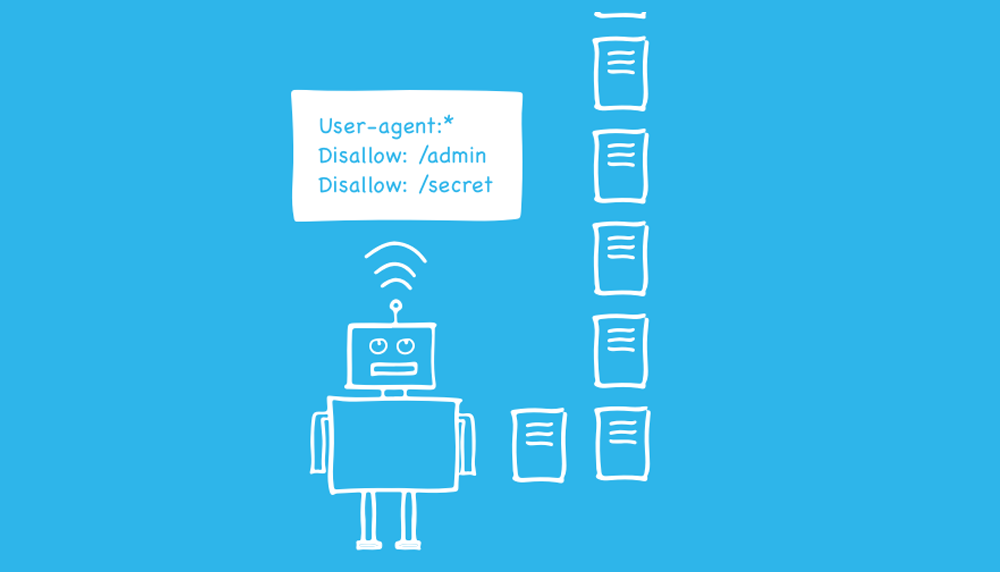
Crawlers follow the rules in robots.txt files, which regulate how they interact with your website. Your robots.txt file communicates whether there are any pages on your website that you do not want visitors to be able to view and crawl. When a crawler hits your page, it looks first at the robots.txt file.
Remember, though, that your robots.txt file is only a guideline. For instance, the malicious robots that hackers utilize can disregard the directives in your robots.txt file.
Furthermore, robots.txt files are accessible to everyone so that anyone can find yours, and you can find anyone else’s. Therefore, a robots.txt file should only be used to give crawlers instructions, never to hide information.
Expert Tips for a Search-Optimised robots.txt

Instructions for search engines are contained in a robots.txt file. Using it, you may instruct search engines on how to crawl your website more effectively. You can stop them from crawling certain areas of your website. In SEO, the robots.txt file is crucial.
Keep in mind the following best practices when deploying robots.txt:
- When adding modifications to your robots.txt file, use caution because doing so could render significant portions of your website unavailable to search engines.
- Your website’s root should contain the robots.txt file accessible via http://www.example.com/robots.txt.
- The robots.txt file only applies to the complete domain, including the protocol (http or https) on which it resides.
- Different search engines have various ways of interpreting instructions. By default, the first directive that matches always prevails. However, Google and Bing favor specificity.
- As little as possible, avoid utilizing the crawl-delay directive for search engines.
FAQs
Is robots.txt a security hole?
The mere existence of the robots.txt file presents no security vulnerability.
Is robots.txt an old file?
No, Google stopped assisting with the unofficial robots.txt no index directive in September 2019.
Conclusion
You can evaluate your robots.txt using various tools, but we always prefer to validate crawl directives directly from the source.
Before implementing any modifications, make sure to test them thoroughly. You wouldn’t be the first to unintentionally block your site with robots.txt and disappear from search engine results. you should also read about If Meta Robots Tags Affect Search Rankings.