
As AI models rapidly inhale online content, web publishers are trying to figure out limits. Enter llms. txt—a plain text file that is used to instruct large language models (LLMs) what they can and cannot use when training. Like robots. txt before it, llms.txt could redefine the way the internet uses AI.
Contents
- 1 llms.txt Explained: What is llms.txt?
- 2 How llms.txt Works Behind the Scenes?
- 3 Why Was llms.txt Created?
- 4 Are Brands and AI Companies Buying In?
- 5 Thinking About llms.txt Strategically
- 6 Challenges & Limitations of llms.txt
- 7 The Bigger Picture: Content, Control & AI Governance
- 8 Why You Should Care—Even If You’re Not a Publisher
- 9 Conclusion: A Tiny File, a Huge Signal
- 10 FAQs
llms.txt Explained: What is llms.txt?
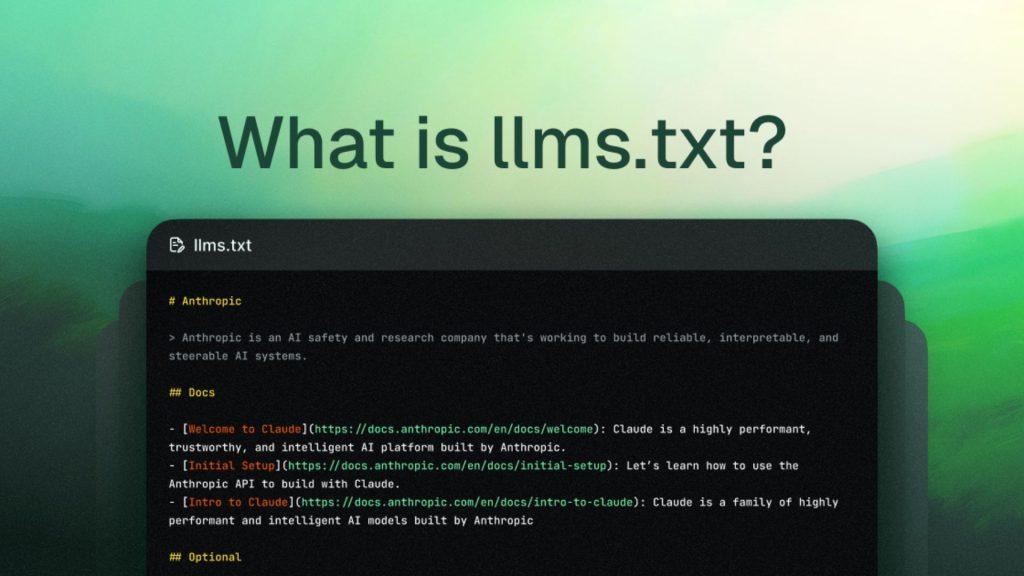
llms.txt is a recent proposal to include a file for all internet protocols and plain text, which would be placed at the root of a site to express a publisher’s preference regarding whether their content should be used to train large language models (LLMs). Similarly to how robots. txt was created to tell search engine bots what to do, this is what llms.txt wants to do to the AIs.
It enjoys an advisory role. The file tells the LLM developers, “These are the things you can use (or not!) on my site.” It has no jurisprudential weight (yet), but it is a signpost in the ever-evolving relationship between the creator of the internet and the creator of artificial intelligence.
It’s easy to give an example. A line such as User-Agent: gptbot refers to OpenAI’s web crawler, and Disallow: /premium-content instructs that bot to ignore certain parts of the site. Similarly, “User-Agent: anthropic” “Disallow:/” would have blocked Claude’s robot from the entire domain.
Popular user agents in llms.txt are GPTbot on the OpenAI API, Anthropic on the Claude models from Anthropic, and Google-extended on the Google AI crawlers.
You shouldn’t have any trouble with llms.txt. Webmasters should create a plain text file named llms.txt and place it under the root of the webpage. They will put access symmetry on all of their AI bots, etc. These are more like counterparts to the robots. txt system and give the copyright holders the opportunity to set boundaries, at least in theory, as to how their content should be interpreted by AI.
The file is just a simple one, but it could have far-reaching consequences for digital content and AI training.
How llms.txt Works Behind the Scenes?
At its core, llms.txt functions similarly to robots. txt, whose goal is a different type of bot. While robots. txt was used to tell search engine robots like Googlebot or Bingbot to crawl, llms.txt is directed to AI crawlers that scrape data in order to train large LMs.
When a spider comes to the site, it will look in the root directory for control files such as robots. txt or sitemap. txt. If it finds llms.txt, it parses the instructions in order to know what to do and how to do it. These instructions can include whether they are allowed to crawl the entire site, limited to certain directories, or blocked from crawling the site.
But unlike search engines, most of which have longstanding conventions around obeying robots. txt, compliance with sitemap. txt is currently voluntary. There is no enforcement. An AI agency might choose simply not to tap the file, and the website owner has no recourse but legal contacts and documents.
LLMs & Robots. txt
While robots. txt is universally respected by search engines, llms.txt has not been standardized or may not be a formal protocol. The file itself can be disregarded or interpreted differently by AI developers. For content makers and publishers that want a firm handle on how their intellectual property is employed, that’s bad news.
A related difference is that robots. txt influences how your content shows up in search results and can even affect your SEO and user traffic. llms.txt, meanwhile, determines whether that content is scraped en masse to enhance or train language models—a much less visible but potentially more pernicious proposition.
In sum, while llms.txt offers some way to signal AI-specific content restrictions, there is no agreed-upon enforcement or anything, and it’s all “take their word for it” and “hopefully AI companies are ethical or something.” This is effective in the sense that it is based on mutual recognition rather than regulatory control, and this represents a significant limitation at the outset.
Why Was llms.txt Created?
The emergence of llms.txt is closely related to mounting worries about how big language models are trained. But with the explosion in recent years of generative AI—a type of network that can generate photos, audio, or text that was not fed to it—most companies have trained models on enormous amounts of publicly available web data, including blogs, discussion groups, scholarly articles, news stories, and fiction.
This sent chills down the spines of some content creators and companies. Their work was being harnessed, often without their consent, to power commercial AI programs. This practice breached ethical and legal boundaries, particularly when artificial intelligence-created products began rivaling the sources from which they’d been trained.
News organizations and journalists also griped that AI models were rewriting their articles without crediting them, causing a decline in traffic to the original work. Artists and writers were incensed that this AI was poetry and art aping their intellectual wares without the necessary acknowledgment or compensation. Teachers and scholars expressed anxiety over the lack of references to scholarly material.
Against this backdrop, llms.txt was a grass-roots mechanism, a digital signal that allowed creators and publishers to assert boundaries. It does something really simple that matters: it gives webmasters the power to respond with a “no” to all the AI companies that want to collect their data and use it to train a model.
At this moment, it was not a moment too soon. In 2023, major publishers like The New York Times revised their terms of service and banned AI scraping. By 2024, several similar allegations had been made against the company by other AI companies for their illegal use of the content. The momentum to create digital content rights had expanded by 2025, and llms.txt took off as a (techneuterbot) tool to help guard against unethical AI.
llms. Although it lacks the cover of a law, llms. txt offers a visual way to indicate online consent. It has given content creators the dereferencing option as a first step of reclaiming control, which they had lost with the blanket control regulation.
Are Brands and AI Companies Buying In?
The value of llms. txt will end up depending on adoption not only from content publishers but also from AI companies. The response to it has, to date, been overwhelmingly mixed, if growing.
Meanwhile, on the publishing side, many well-known institutions have taken up llms. txt. One of the first to put AI bots’ noses out of joint by blocking them from scraping its content was the New York Times. Others, like CNN, Bloomberg, and Vox Media, have followed suit. The legal concerns that haunt these companies are real enough: They worry their work will be repurposed by AI without their permission, or that their websites will lose traffic.
Specialized publishers (e.g., academic databases, subscription news services, and industries full of copyrights) have also shown interest in llms. txt as a protective tool.

Who’s supporting this?
The protocol has been acknowledged by the list of some of the biggest companies on the AI company side. OpenAI just posted an introduction to a bot it is calling GPTBot and LogBot, and there are people, ourselves included, who have confirmed that it is checking for llms. txt files when crawling websites. Google’s AI division has published an AI command center, named Google Cloud, that web admins can deploy to control access to its Bard and Gemini models. And Anthropic, the company that made Claude, has also said it tracks llms. txt directives.
But not every human AI company is willing to go that way. Others haven’t yet revealed their crawlers or haven’t said one thing about playing nice. The opacity is concerning in how consistently llms. txt is being followed.
There is, however, a catch: no one is enforcing them. Even if a company behind an AI service says publicly that it values llms. txt, website owners have no way to verify that compliance. This sows a level of distrust.
Still, the growing number of organizations implementing llms.txt suggests that the protocol is gaining legitimacy.
Thinking About llms.txt Strategically
Implementing llms.txt isn’t a technical decision alone—it’s a strategic one. The risks and benefits of letting AI use their content are left to the choice of owners, publishers, educators, and content creators of websites.
One should not allow AI crawlers for a few reasons.
To begin with, original writing, be it journalistic, scholarly, creative, or educational, is born of intellectual work. Not being able to tackle it, as one can take it to be included in AI models without credit or profit, may cause a sense of stripping of possession.
Competition is one of the issues for some publishers.
When AI systems pick up the information and create a similar kind out of it on their own, the users might cease to go to the source. This may decrease the flow of traffic to the sites, the advertisement earnings, and the increase in subscription numbers.
There is the issue of privacy.
Not all web content is made to be consumed by machines. Informal congregations, individual blogs, and exclusive communities might want to have their voice and expertise stay away from the huge corporate training sets.
Conversely, other creators find it advantageous to make their content usable. In the case of open-source platforms, the addition of AI models can be part of the mission of researchers or organizations that advocate public education. In these cases, llms.txt can be configured to allow AI bots access, either fully or selectively.
One of the most useful features of llms.txt is the ability to permit certain bots while blocking others. As an example, a given location could have the AI models in Google open to them and the bot in OpenAI blocked, depending on their degree of association or trust.
This makes llms.txt a strategic tool rather than a binary switch. It facilitates micro-level choices about the access of data and is adjusted to the objectives and principles of every site.
Of great importance to marketers and SEO experts is knowing how AI mechanisms relate to publicly available content. When the search engines or even LLMs are themselves generating summaries or answers derived from scraped data, then access is the content strategy. The same applies to learning institutions and nonprofit organizations, which want to ensure their integrity yet reach out to larger populations.
Ultimately, llms.txt isn’t just about blocking bots—it’s about asserting choice in a digital ecosystem where creators have often been sidelined. Therefore, it can be regarded as one of the rising trends of ethical and transparent development of AI.
Challenges & Limitations of llms.txt
Despite its potential, llms.txt has notable limitations that must be acknowledged.
To start with, it is not enforceable. Unlike copyright protections, which can be upheld in court, llms.txt is a voluntary protocol. Unless other agreements are signed, AI companies are not bound to carry out their instructions.
Second, there is a lack of a transparency mechanism. Once you publish an llms.txt file, there’s no way to verify whether an AI company is respecting it. No matter the restrictions, site owners cannot trace the bot activities and determine whether their data was accessed.
Third, llms.txt has no retroactive effect. Scraped content that was used in the past to train models is not impacted. This creates a large loophole in security, especially in websites that have large archives.
Fourth, the protocol is non-standardized. There is no standardized naming convention for AI bots yet, and the current situation is that the publishers find it hard to model their files properly. The technical non-satisfaction curbs the functionality of the file.
Finally, unintended consequences may be caused by misconfiguration. If implemented incorrectly, an llms.txt file might block legitimate bots or restrict content that could benefit from exposure.
While it offers a step forward, llms.txt should be viewed as a signal of intent rather than a guarantee of protection.
The Bigger Picture: Content, Control & AI Governance
The development of llms.txt signals a deeper shift in how we think about content and control in the age of artificial intelligence. The data that LLMs are trained on is a vital resource as they become more powerful. The world of websites, articles, forums, and blogs that used to be regarded as mere information is now being taken into training models of high power.
This provokes some deep issues. Who is the proprietor of knowledge on the web? Artists/creators are supposed to get compensation when their works are utilized to train commercial AI applications? What is the trade-off between innovation and consent?
These queries anthologize a deeper struggle between open access and electronic independence. Although the use of the internet was initially meant to be free and shareable, with the advent of AI, commercial elements have come along, and this alters the playing field. The worth of content no longer lies only in the way it can help people know, but also in the way it can make the machines learn.

llms.txt is one response to this changing landscape. It does not eliminate all the issues, but it provides a level of control that is absent. It can be a central pillar of a digital governance of the future, together with privacy regulations, licensing platforms, and consent mechanisms.
Whether viewed as a stopgap or the beginning of something bigger, llms.txt is part of an important conversation about the future of human-created content in an AI-driven world.
Why You Should Care—Even If You’re Not a Publisher
Even if you don’t run a media company or publish articles daily, llms.txt could still affect you. AI crawlers may attack your content in case you are a business site owner, a nonprofit organization, a blog writer, or even one of the contributors in the forums.
Today, AI is used in a variety of programs, including customer support bots, search programs, content summaries, and virtual assistants. Such tools usually use the information obtained from the web, including yours. This implies that your writing, teaching, or the product descriptions you just wrote might train a model without your consent.
Implementing llms.txt gives you a way to participate in the conversation about how your content is used. Even when making that decision, it is better to make it consciously because at least you are in control when you open up to AI.
Understanding llms.txt also equips you for future developments. Since digital regulations are changing and ethical AI applications are on the rise, it will become necessary to understand how your content is handled by machines. Just as web analytics, privacy policies, and cookie banners became standard tools of digital literacy, llms.txt may soon join that toolkit.
In short, llms.txt is not just a tool for publishers—it’s a signal that everyone, from individual creators to global brands, has a role in shaping the digital rules of engagement.
Conclusion: A Tiny File, a Huge Signal
llms.txt may be small, but its significance is growing. No, it is not really about stopping bots but about beginning a discussion of permission, possession, and justice within the era of AI. It is important to know that you can block, permit, and even customize. Even a silhouette is data in the era of AI.
FAQs
Will all AI bots respect llms.txt?
Not necessarily. Although AI businesses have been vocal about their commitment to respect it, not all of them will do so. The system is based on goodwill and transparency, but they are biased in the industry.
Does llms.txt protect content already used in AI training?
No. It is only applicable to future data collection. If your content was previously scraped and used in model training, llms.txt won’t remove it from existing datasets.
Is it possible to block certain AI bots and enable others?
Yes. The protocol is selective and block-friendly. With the different user agents, you can specify different rules to use, thus gaining more control of how your content is accessed.
Does llms.txt replace copyright or legal action?
No. It supplements but does not replace legal defenses. To be enforced more, the copyright registration, a licensing model, or a legal agreement should also be considered by the publishers.