

Danny Sullivan shows why homogenization may lead a title of the article search to momentarily relegate the original content to page 2 of the results.
A publisher from The Verge claimed that a new item had been duplicated and substituted on site one of Google’s search outcomes. Danny Sullivan explains why this is the case.
Publishers are irritated by content that has been copied and ranked.

See Also: Google On How To Improve SEO Audits
Plagiarized content which outshines the original has been a source of frustration for publishers for several years.
A misconception is to blame for some of the complaints. For example, Google has no idea what to do with a gibberish phrase like randomly chosen words from an article. Because it isn’t a true search request and that there is no solution for a gibberish phrase.
As a consequence, Google defaults to a text search, which implies that search terms are returned based on the keywords in a search query complementing the terms on a web page.
The true test of whether duplicated content outscores original material is when duplicated content outshines unique content for targeted keywords that people are searching for.
Contents
The First Page Is Entirely Made Up Of Stolen Content
A scan for a title from a fresh piece resulted in Google revealing a complete top ten that is entirely made up of stolen content, according to The Verge.
Danny Sullivan admitted that when people search with a title, they expect the results at the top of the first page, not on page two.
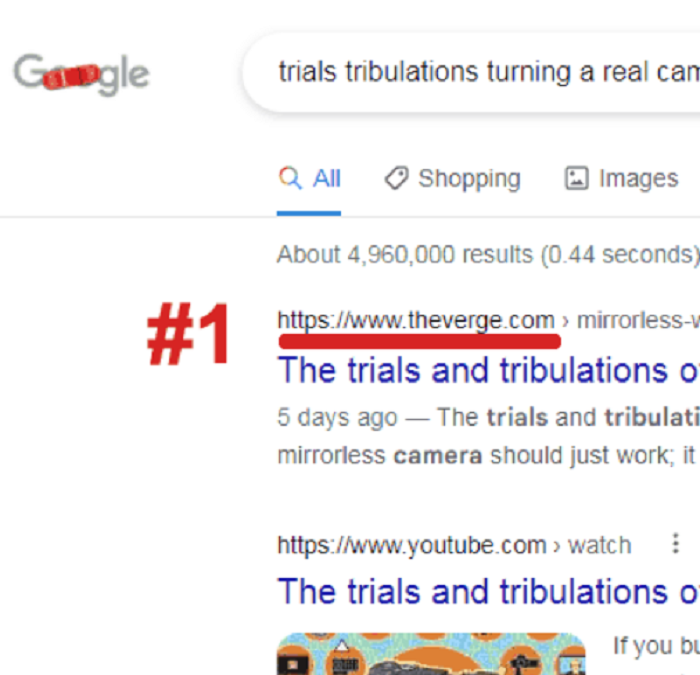
However, he also pointed out that browsing by headline isn’t always how most people search.
It’s debatable if Danny’s response is appropriate. Many individuals search the headline of an article whenever they want to share it with a colleague or on social media, which is a legitimate argument. So there’s a good explanation why folks who aren’t the creator of an article might look up the title.
Alternative Search Results From Search Queries
Danny Sullivan’s upcoming tweet tries to explain how a query with a lot of aspects. Little term causes Google’s algorithm to decline out and start returning google outcomes that are more like ancient keyword searches. Where the browse results aren’t premised on search intent or links, but only on the keywords themselves.
There is a research intention behind browsing for titles, as I explained earlier. It’s possible that Google hasn’t identified “headline-oriented searches” as search queries that should be detected by the algorithm.

So, in this case, should a website rank twice since a user may prefer to view the original story at the peak of the search outcomes, even though it’s currently in the Top Stories segment?
The news piece should display at the peak of the search returns after the Top Stories segment has vanished.
This is an intriguing dilemma in which Google must assess what is fair to the publisher while also being valuable to the searcher.
Should A Page That Appears In A Top Stories Outcome Be Ranked Twice?
However, the situation that has arisen presents a unique scenario. What occurred is that if a new website already appears in the Top Stories highlighted outcomes, at the top. Google will just not place the article’s title at the top of the standard search results.
Top Stories is a highlighted outcome in which Google displays news stories that are relevant to the search query.
So, should Google display the same content repeatedly? Once during the Top Stories section and then twice at the top of regular search results?
See Also: IndexNow Enables Data Sharing Between Search Engines