
The crawling procedure starts with collecting internet URLs and backlinks supplied by site operators from previous scans. The crawlers employ hyperlinks on these domains to find other web pages when they browse them. Here, you will find the complete guide on how search engines crawl and index.
New websites, modifications to established platforms, and expired backlinks are all given extra consideration by the program. Computer programs decide which websites to scan, how frequently to crawl them, and how many web pages to get from them.
Google Search Console allows site operators to offer comprehensive guidelines on analyzing web pages on respective websites, asking for a recrawl, or opt-out of searching entirely via a document named “robots.txt.”
Google doesn’t ever charge a fee to crawl a page more regularly; instead, it offers all sites with identical features to access the same tools on all websites. Crawling or indexing web pages is the initial stage in a lengthy procedure of figuring out what websites are all regarding so that websites can present them as responses to user inquiries.

The way search engines scan and analyze sites is continually evolving. Learning ways Google and Bing handle the work of scanning and categorizing sites might help you design web visibility tactics.
Crawling
Crawling is the procedure through which search results dispatch a group of bots, also referred to as crawlers and spiders, to look for newer and current information. Material can take many forms, including a website, a picture, a clip, a Document, etc. But irrespective of the structure, hyperlinks are put to use to find it.
Googlebot begins by retrieving a few online sites and then analyzing those sites’ hyperlinks to discover new URLs.
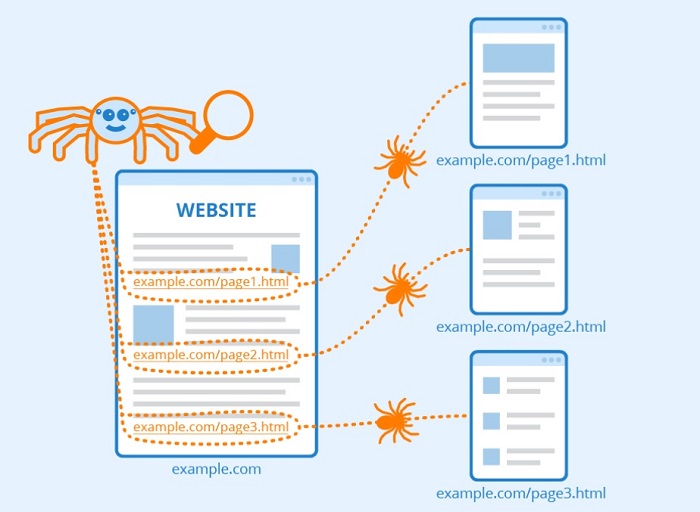
By following this route of hyperlinks, the crawler can identify new material. They can add it to its Caffeine index, a vast collection of newly identify URLs. They become accessible afterward when a user is looking for material that the information on that URL is a perfect fit for.
Indexing
After completing a web page scan, the rankings procedure commences with indexing. Indexing is the process of classifying a webpage’s contents to Google so that they can evaluate it for results.
Whenever you add a new webpage to your website, there are several methods for it to get index. The quickest way to have a web page rank is to do nothing.

Because Google’s crawlers track hyperlinks, if your website presents in the index and the new material connects from inside it, Google will ultimately find it and add it to the database.
See also: IndexNow is a Major Change to Search Engine Indexing
Getting a page index quicker
The earliest and most effective method of drawing a search engine’s focus to information is using XML sitemaps.
An XML sitemap gives search crawlers a catalog of all the web pages on your website as well as other information such as when it was the last update.
A sitemap could be upload to the Bing through Bing Webmaster Tools and Google through Search Console.
Conclusion
To summarize, optimizing a website for search engines starts with solid content and concludes with submitting it to be index.

Moving that information indexed, whether using an XML sitemap, Google Search Console URL Submission Tool, Bing Webmaster Tools, or IndexNow, is the first step in getting your webpage to the top of the search results. How Search Engines Work crawl and index into the inner workings of search engines and the fundamental aspects that impact search engine results pages.